Step 3. Quality control
Note
- Consideration for the analysis.
Steps 3b and 3c can be done either in the interface or with the command-line code in the “merging.batch.harmony.R” in the project directory.
- Prerequisite
Completed the step 1. foramtting and have the two files (matrix.csv and meta.data.csv files in the 1_SeuratQC folder)
3a. Quality control of a Seurat object
This section describes the Seurat QC process for human samples with 10x Genomics.
Upload both the meta-data.csv file and the matrix file (.csv.gz, .csv or .h5).
Add the file name, which will be identical to the previous file name.
- Select the data origin, as it will change the cut-off settings.
10x Genomics >2500 features (transcripts per cell), are deemed to be doublets.
BD Rhapsody Immune panel > 150 features, are deemed to be doublets.
Check that the file was uploaded
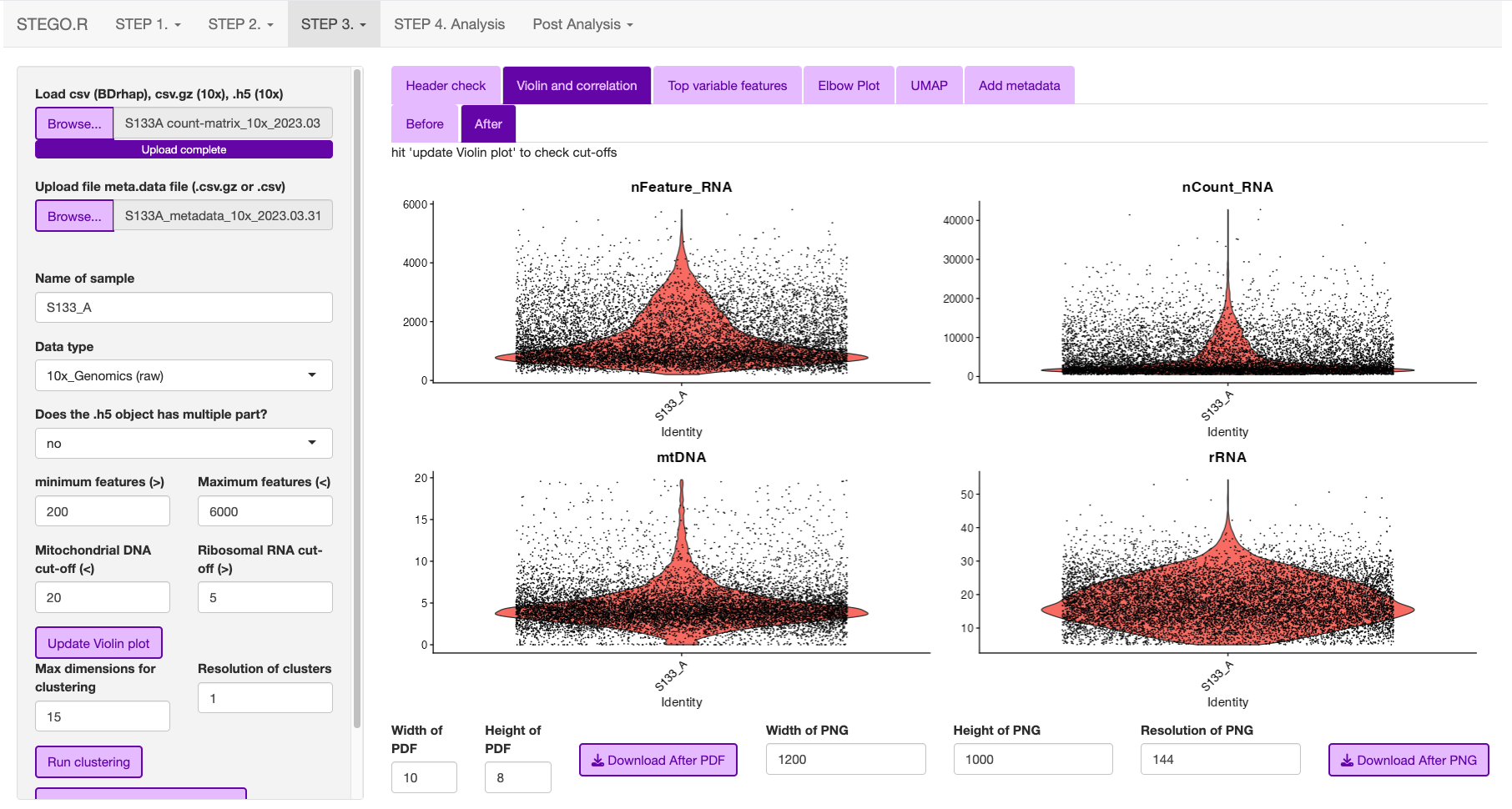
- Look at the first volcano plot “before” tab, as we need to check the cut-off for the MtDNA and rDNA cut-offs
MtDNA standard cut-off less than 20%
rRNA standard cut-off is greater than 5%. If there is no rRNA genes identifed, set value to 0 or the program will crash due to no cell’s remaining.
Once the settings have been configured, hit update. This will add the File name.
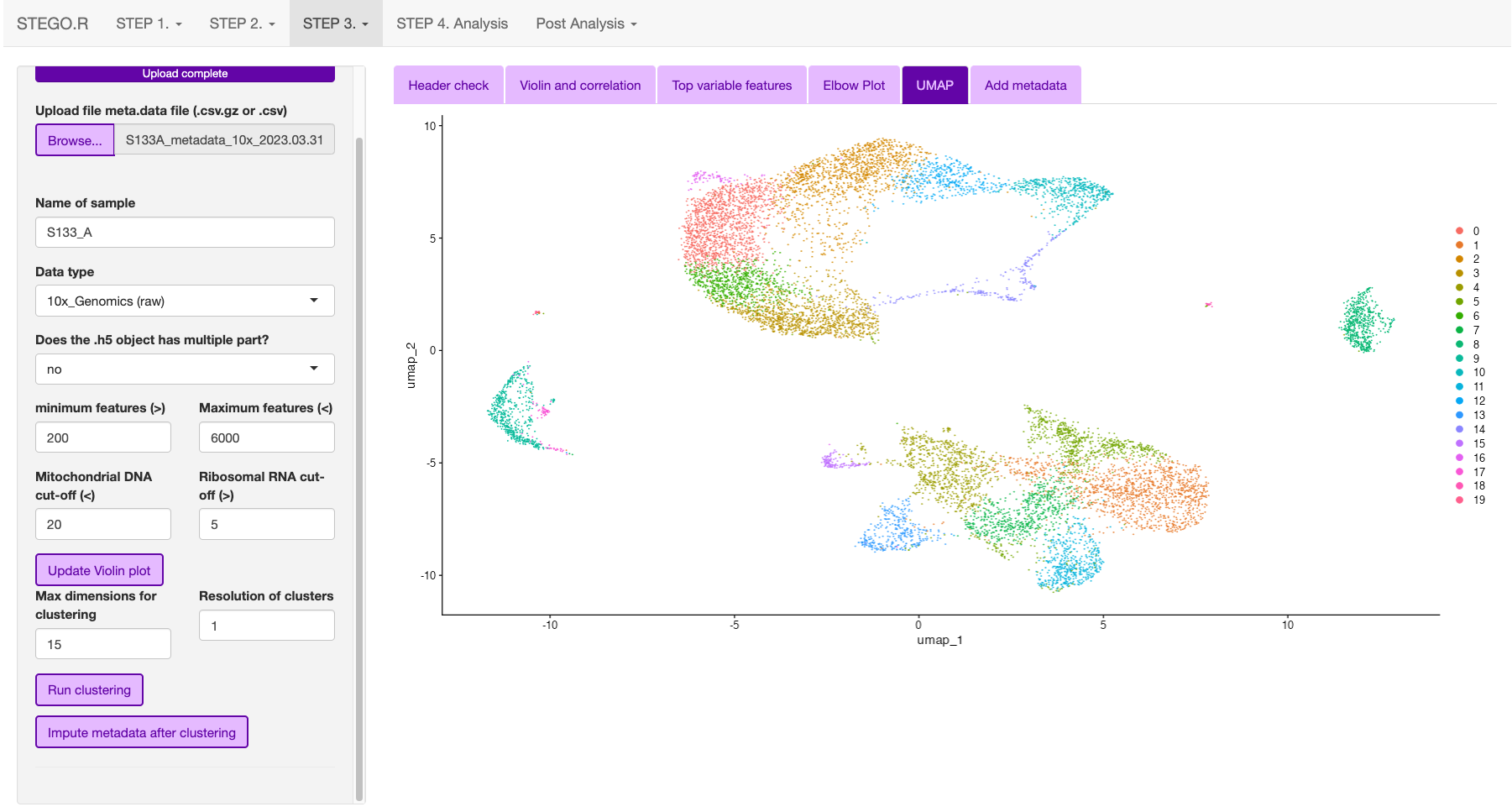
The user can then inspect the presence of the top variable features, elbow plot and Heatmaps. The latter two plots are to aid in setting the number of dimentions to use for the UMAP dimentional reduction. Default is set to 15. The resolutions are used for the unsupervised clustering. Note: we recommend using scGate for the annotation rather than the unsupervised clusters as it is not suitable for identifying subtle differences in T cell sub-populations.
In the side panel, hit the “Run clustering” button to run the dimentionality reduction.
In the “Add meta data”, first check that the file has uploaded correctly.

Now your file has completed the Seurat QC and has had the TCR sequences added to the meta-data. click the “Download Seurat” object and save it to the “2_SCobj” folder.
command-line equivalent
Once the user has identified the parameters for filtering, we recommend using the command-line function that automates this process.
###### Step 3a. Automated file filtering ------
# default parameteres: folder = "1_SeuratQC", dataset_type = "10x", species = "hs", features.min = 200, features.max = 6000, percent.mt = 20, percent.rb = 5, dimension_sc = 15, resolution_sc = 1, limit_to_TCR_GEx = F, save_plots = T
# run defaults for 10x based on seurat.
automated_sc_filtering(dataset_type = "10x")
# BD Rhapsody (immune panel) -----
automated_sc_filtering(dataset_type = "BD_rap",features.min = 45,features.max = 160, percent.mt = 0, percent.rb = 0)
3b. Merging multiple Seurat objects and batch correction.
This section explains how to merge multiple .rds objects and correct for batch effects.
Merging
From the “2_SCobj” upload all the .rds files.
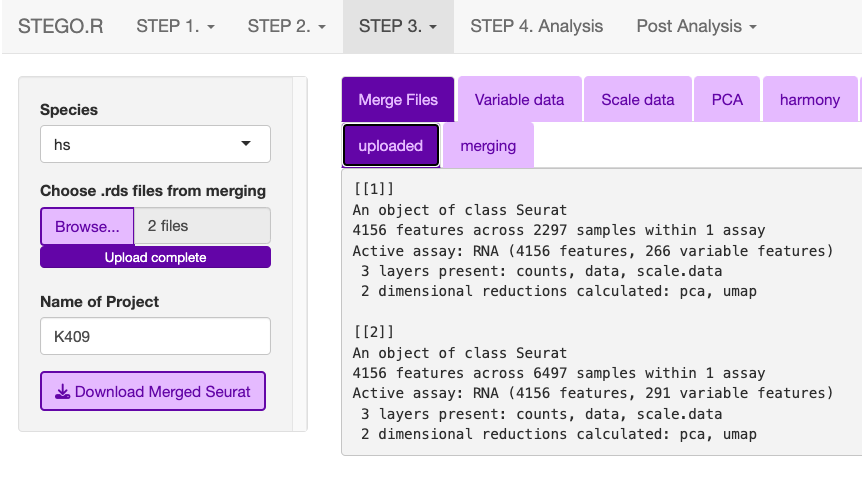
Download the merged.rds object
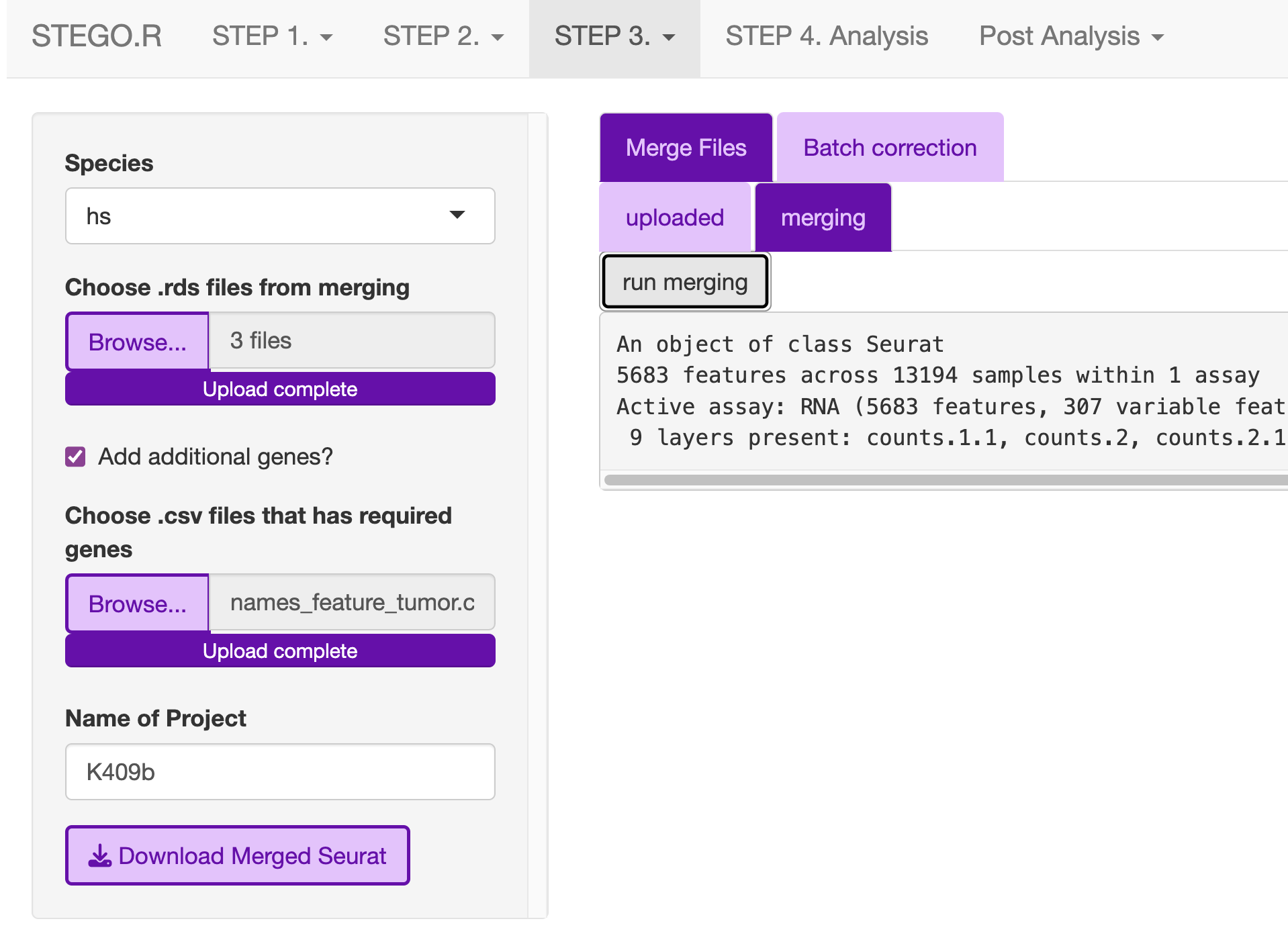
** For repeated file merging and annotating, the program window may disappear, so we recommend merging and annotating using command-line functions **
require(STEGO.R)
###### merging seurat object ------
# Check that you are in the correct working directory with your RDS files
merging_multi_SeuratRDS(set_directory = "2_scObj/", merge_RDS = F, pattern_RDS = ".rds$")
# once that is check, switch merge_RDS to TRUE or T
sc_merge <- merging_multi_SeuratRDS(set_directory = "2_scObj/", merge_RDS = T, pattern_RDS = ".rds$")
# merges the different layers in V5 of seurat
sc <- JoinLayers(sc_merge, assay = "RNA")
# save the merged file - it will not have the scaled data and PCA stored any more due to the merging process.
saveRDS(sc_merge,"2_scObj/sc_merge.rds")
batch correction
Wait for the files to finish uploading before proceeding
Update the Project name e.g., BreastCancer
- Hit the bottons in each tab in the following order:
Run VariableFeatures
Run Scale
Run PCA
Run Harmony Note: Harmony R package is used for the batch correction.
Run Dimentional Reduction
Once completed click the “Download merged Seurat”
Note
* Visit Harmony publication for more detail.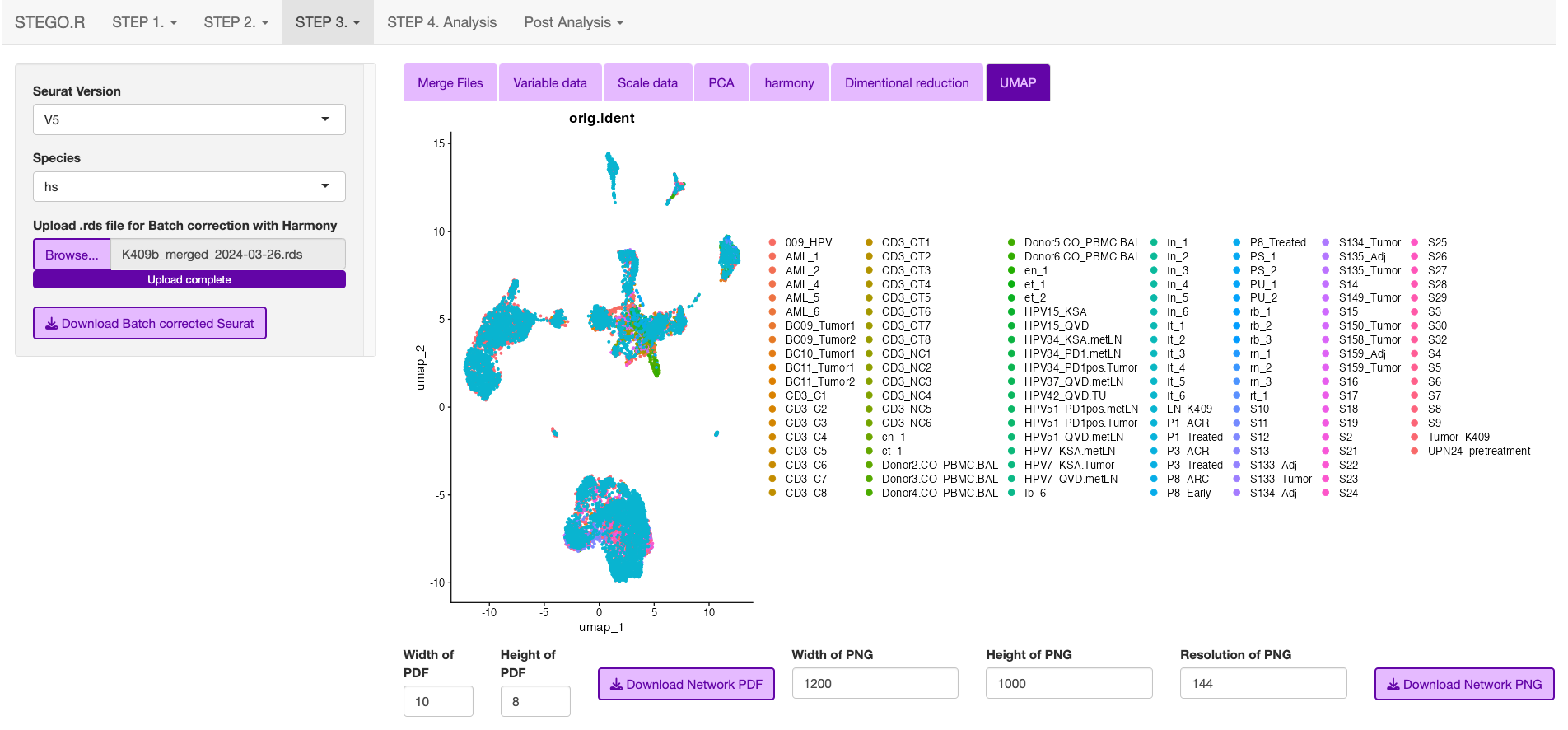
Note: Depending on the number of files, and total number of cells will impact the speed of merging
If you have more than a few files to merge and annotate, we recommend using the following code:
require(STEGO.R)
sc <- readRDS("2_scObj/sc_merge.rds")
## perform the harmony batch correction ------
sc <- harmony_batch_correction_1_variableFeatures(file = sc)
sc <- harmony_batch_correction_2_Scaling(file = sc, Seruat_version = "V5")
sc <- harmony_batch_correction_3_PC(file = sc)
sc <- harmony_batch_correction_4_Harmony(file = sc)
saveRDS(sc,"2_scObj/sc_harmony.rds")
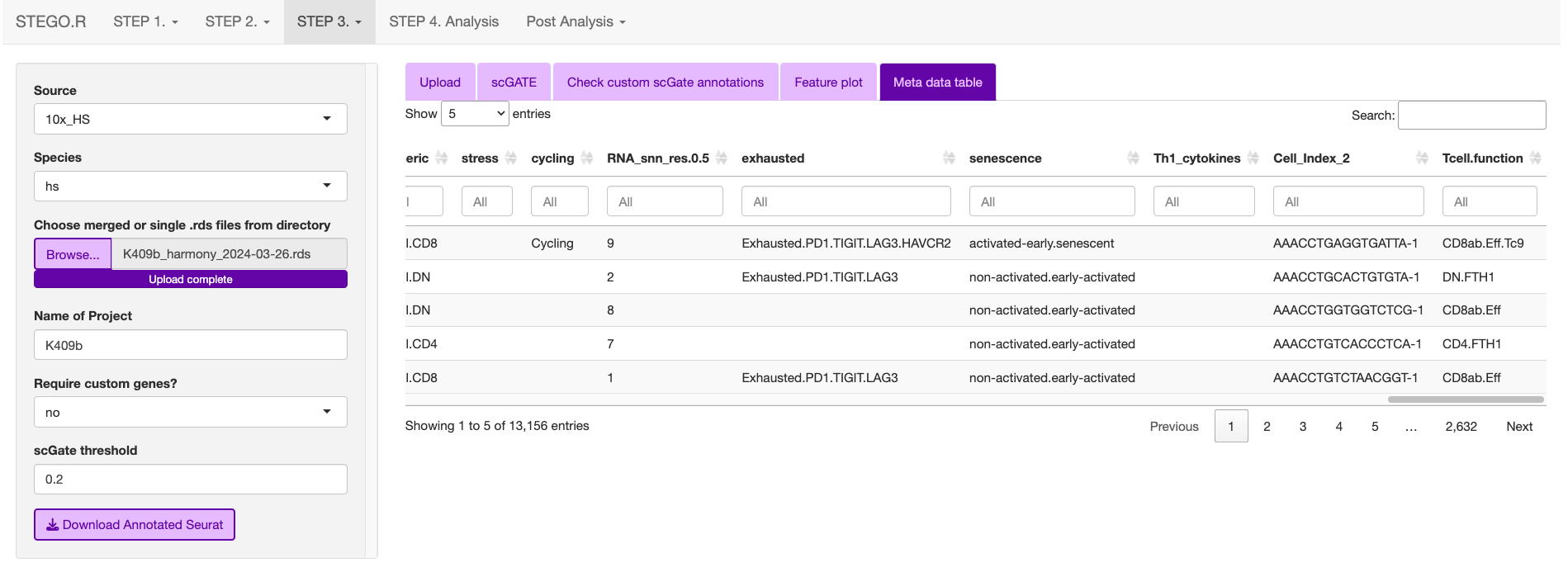
3c. Annotating the Seurat object
This section describes how to annotated the files either from the “default” and/or “custom” modules with scGate. If you have large files, we recommend using scripts and not the interface.
Upload the merged file to commence the annotation process.
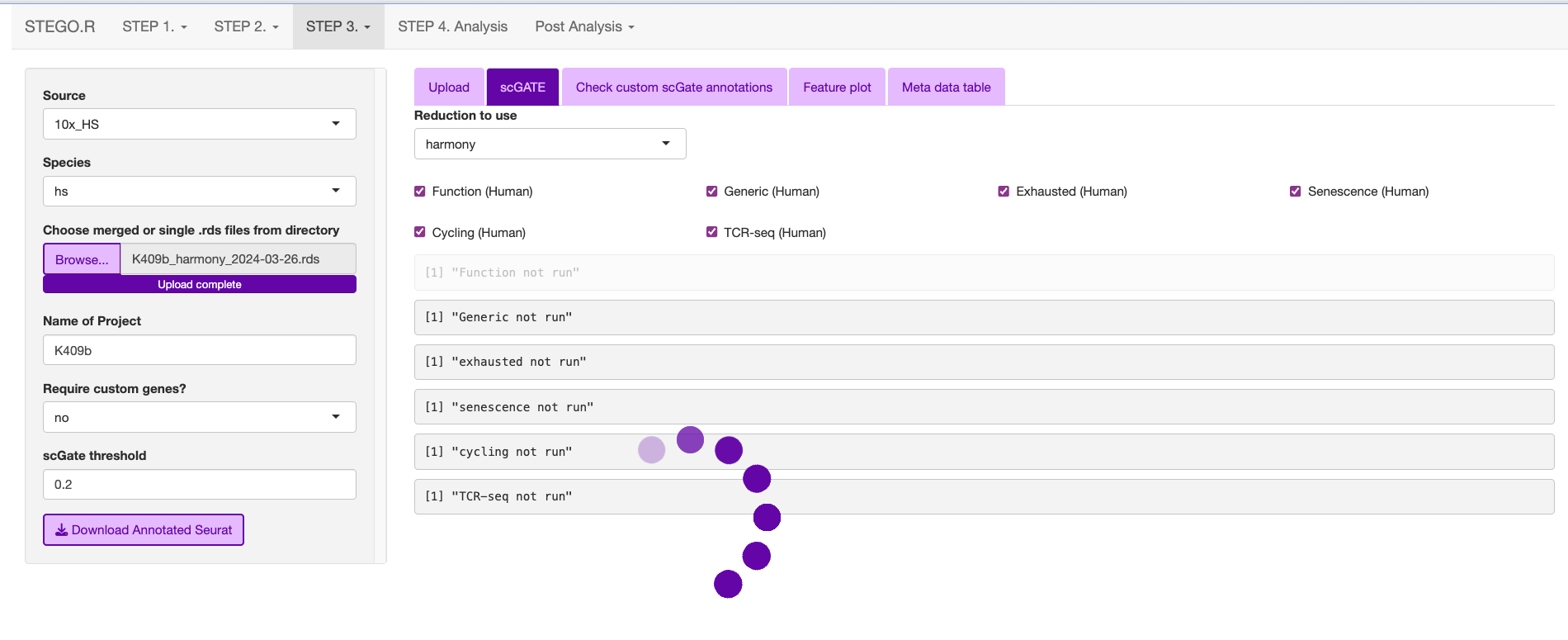
This is what the window will print once the annotation is completed.
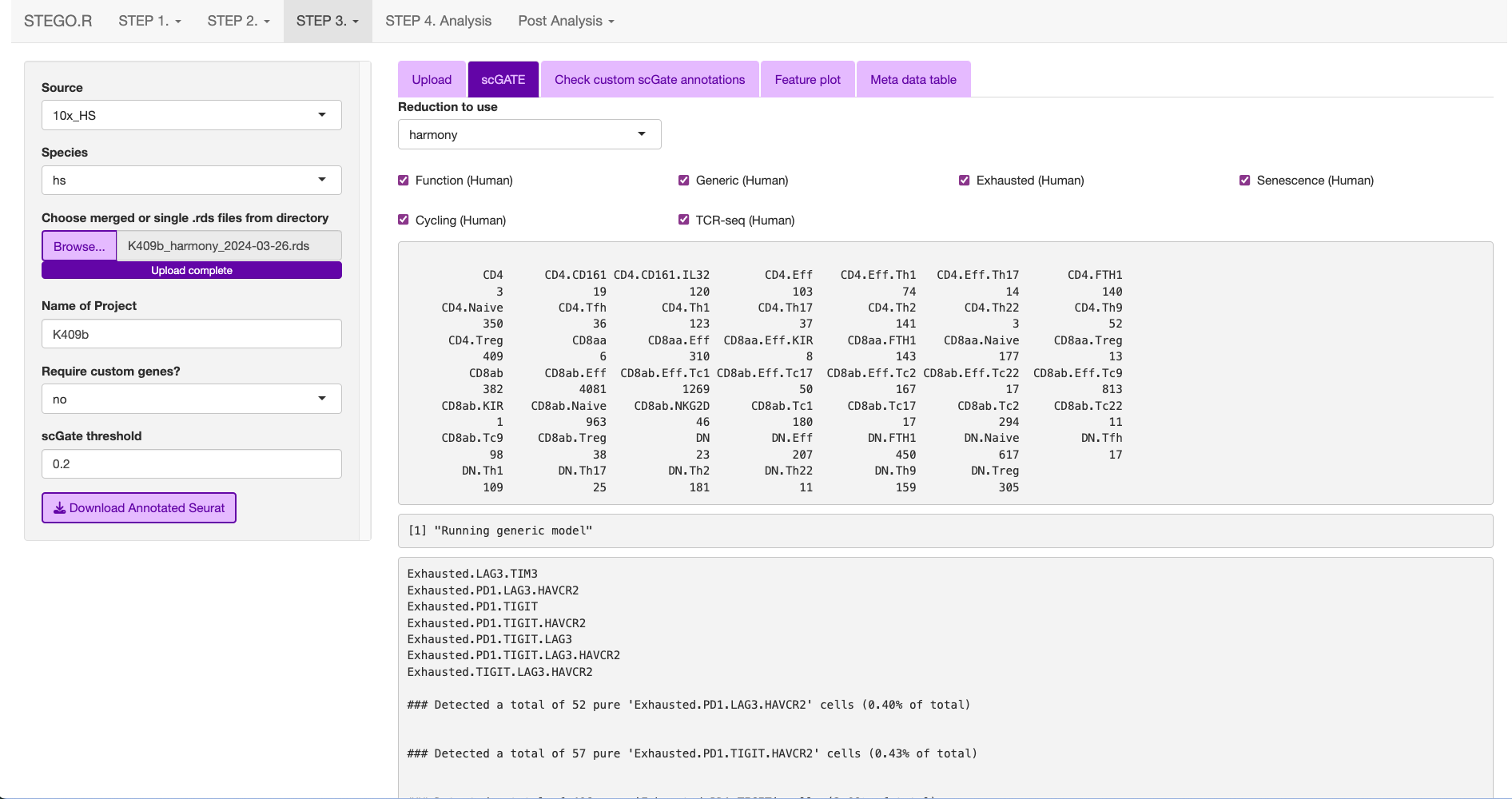
The annotations are added to the end of the meta data table in the Seurat object.
require(STEGO.R)
#### annotating Seurat object -----
sc <- readRDS("2_scObj/sc_harmony.rds")
sc <- scGate_annotating(
file = sc,
TcellFunction = T,
generic = T,
immune_checkpoint = T,
senescence = T,
cycling = T,
Th1_cytokines = T,
TCRseq = T,
threshold = 0.25, # change to 0.55 if you use the focused BD Rhapsody immuen panel
reductionType = "harmony",
chunk_size = 50000
)
sc@meta.data$Cell_Index_old <- sc@meta.data$Cell_Index
sc@meta.data$Cell_Index <- rownames(sc@meta.data)
saveRDS(sc,"3_analysis/sc_anno.rds")
Default annotation models with scGate
The scGate threshold was set to 0.2 for full capture and 0.55 for the immune panel (<400 transcripts).
- Human
TcellFunction (see Annotation table)
- immune checkpoint
Based on four markers: PDCD1 (PD-1), TIGIT, (LAG-3) and H
- Senescence
Activated (B3GAT1+CD28+)
activated-early/senescent (B3GAT1-CD28-)
non-activated/early-activated (B3GAT1-CD28+)
Terminally differentiated (B3GAT1+CD28-)
- Cycling (e.g., cell division)
MKI67+TOP2A+
This is the same as cell division
- Th1_cytokines
combination of IFNG and TNF
- TCRseq (meta.data TCR-seq)
MAIT cells (TRAV1-2 TRAJ33/12/20)
iNKT cells ()
possible CD1b/c restricted
ab T cells (excludes the above categories)
gd T cells
Mouse
Note: Under development.
Functional T cell annotations
Annotation Table
Cell type |
Sub-classification |
Transcriptional markers |
|---|---|---|
CD4 |
CD4 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive, KLRB1-, FTH1- |
CD161 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive, KLRB1, IL32- |
|
CD161.IL32 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive, KLRB1, IL32 |
|
FTH1 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive, KLRB1-, FTH1 |
|
Naive |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive |
|
Tfh |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21 |
|
Th1 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3 |
|
Th17 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC |
|
Th2 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4 |
|
Th22 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10 |
|
Th9 |
CD8A-, CD8B-, CD4;CD40LG, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4 |
|
Treg |
CD8A-, CD8B-, CD4;CD40LG, FOXP3 |
|
CD8a |
CD8aa |
CD8A, CD8B-, Cyto-, FOXP3-, KIR2DL1-, Naïve-, FTH1- |
Eff |
CD8A, CD8B-, Cyto, KIR2DL1- |
|
Eff.KIR |
CD8A, CD8B-, Cyto, KIR2DL1 |
|
FTH1 |
CD8A, CD8B-, Cyto-, FOXP3-, KIR2DL1-, Naïve-, FTH1 |
|
KIR |
CD8A, CD8B-, Cyto-, FOXP3-, KIR2DL1 |
|
Naive |
CD8A, CD8B-, Cyto-, FOXP3-, KIR2DL1-,Naive |
|
Treg |
CD8A, CD8B-, Cyto-, FOXP3 |
|
CD8ab |
CD8ab |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1, RORC-, CCR4-, CCR10-, IRF4-, CXCR3-, Naive-, KLRK1- |
Eff |
CD8A, CD8B, Cyto, RORC-, CCR4-, CCR10-, IRF4-, CXCR3- |
|
Eff.Tc1 |
CD8A, CD8B, Cyto, RORC-, CCR4-, CCR10-, IRF4-, CXCR3 |
|
Eff.Tc2 |
CD8A, CD8B, Cyto, RORC-, CCR4 |
|
Eff.Tc22 |
CD8A, CD8B, Cyto, RORC-, CCR4-, CCR10 |
|
Eff.Tc9 |
CD8A, CD8B, Cyto, RORC-, CCR4-, CCR10-, IRF4 |
|
Eff.Tc17 |
CD8A, CD8B, Cyto, RORC |
|
KIR |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1 |
|
Naive |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4-, CCR10-, IRF4-, CXCR3-, Naive |
|
NKG2D |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4-, CCR10-, IRF4-, CXCR3-, Naive-, KLRK1 |
|
Tc1 |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4-, CCR10-, IRF4-, CXCR3 |
|
Tc17 |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC |
|
Tc2 |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4 |
|
Tc22 |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4-, CCR10 |
|
Tc9 |
CD8A, CD8B, Cyto-, FOXP3-, KIR2DL1-, RORC-, CCR4-, CCR10-, IRF4 |
|
Treg |
CD8A, CD8B, Cyto-, FOXP3 |
|
CD8b |
CD8b |
CD8A-,CD8B |
DN |
DN |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive-, FTH1- |
Eff |
CD8A-, CD8B-, CD4-, Cyto |
|
FTH1 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive-, FTH1 |
|
Naive |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3-, Naive |
|
Tfh |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21 |
|
Th1 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4-, CXCR3 |
|
Th17 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC |
|
Th2 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4 |
|
Th22 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10 |
|
Th9 |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3-, RORC-, CCR4-, IL21-, CCR10-, IRF4 |
|
Treg |
CD8A-, CD8B-, CD4-, Cyto-, FOXP3 |
Annotation Details
Cyto = GZMA, GZMB, PRF1, GNLY, NKG7 Naive = CCR7, SELL DN = double negative; Th = T helper, Tfh = follicular T helper, Tc = cytotoxic T cell; Treg = regulatory T cellSimple T cell annotations
Simple Annotation Table
Cell type |
Sub-classification |
Panel |
|---|---|---|
CD4 |
Treg |
CD8A-, CD8B-, FOXP3, RORC- , CCR6-,CXCR6- |
Treg.IL17 |
CD8A-, CD8B-, FOXP3, RORC , CCR6, CXCR6 |
|
Tcm-Tn |
CD8A-, CD8B- , FOXP3- , RORC- , CCR6-,CXCR6-, GZMB-, IFNG-, GNLY-, NKG7-, CXCL13-, IL21-, IL7R, TCF7, CCR7 |
|
Tfh |
CD8A-, CD8B- , FOXP3- , RORC- , CCR6-,CXCR6-, GZMB-, IFNG-, GNLY-, NKG7-, CXCL13, IL21 |
|
Th1 |
CD8A-, CD8B- , FOXP3- , RORC- , CCR6-,CXCR6-, GZMB, IFNG, GNLY, NKG7 |
|
Th17 |
CD8A, CD8B, FOXP3-, RORC , CCR6,CXCR6, |
|
other |
CD8A-, CD8B- ,CD4, CD40LG, FOXP3- , RORC- , CCR6-,CXCR6-, GZMB-, IFNγ-, GNLY-, NKG7-, CXCL13-, IL21-, IL7R-, TCF7-, CCR7- |
|
CD8 |
Tcm-Tem |
CD8A, CD8B,CD4-, CD40LG-, ITGAE-,GZMK |
Tcm-Tn |
CD8A, CD8B,CD4-, CD40LG-, ITGAE-,GZMK-, GZMB-, PRF1-, GNLY-, SELL |
|
Teff |
CD8A, CD8B,CD4-, CD40LG-, ITGAE-,GZMK-, GZMB, PRF1, GNLY, |
|
Teff.TS |
CD8A, CD8B,CD4-, CD40LG-, ITGAE, ENTPD1 |
|
Trm.Teff |
CD8A, CD8B,CD4-, CD40LG-, ITGAE, ENTPD1-, CD160- |
|
IEL |
CD8A, CD8B,CD4-, CD40LG-, ITGAE, ENTPD1-, CD160 |
|
other |
CD8A, CD8B,CD4-, CD40LG-, ITGAE-,GZMK-, GZMB-, PRF1-, GNLY-, SELL- |
|
DN |
DN |
CD8A-, CD8B- ,CD4-, CD40LG-, FOXP3- , RORC- , CCR6-,CXCR6-, GZMB-, IFNγ-, GNLY-, NKG7-, CXCL13-, IL21-, IL7R-, TCF7-, CCR7- |
DP |
DP |
CD8A, CD8B,CD4, CD40LG |
Simple Annotation Table
Cyto = GZMA, GZMB, PRF1, GNLY, NKG7 Naive = CCR7, SELL DN = double negative; Th = T helper, Tfh = follicular T helper, Tc = cytotoxic T cell; Treg = regulatory T cellCreating custom annotation stratergies
The user can add additonal annotations beyond the default.
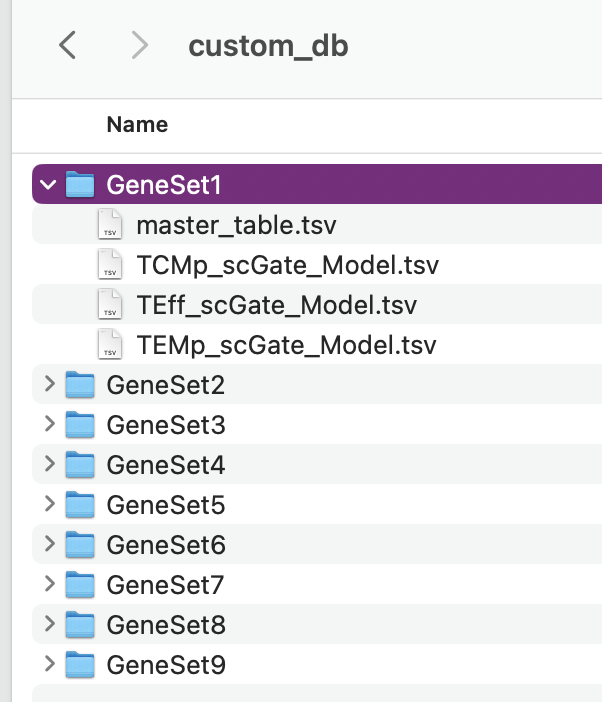
There are nine custom databases that a user can amend. If needed, these can be added to an already annotated file.
Design your custom marker set
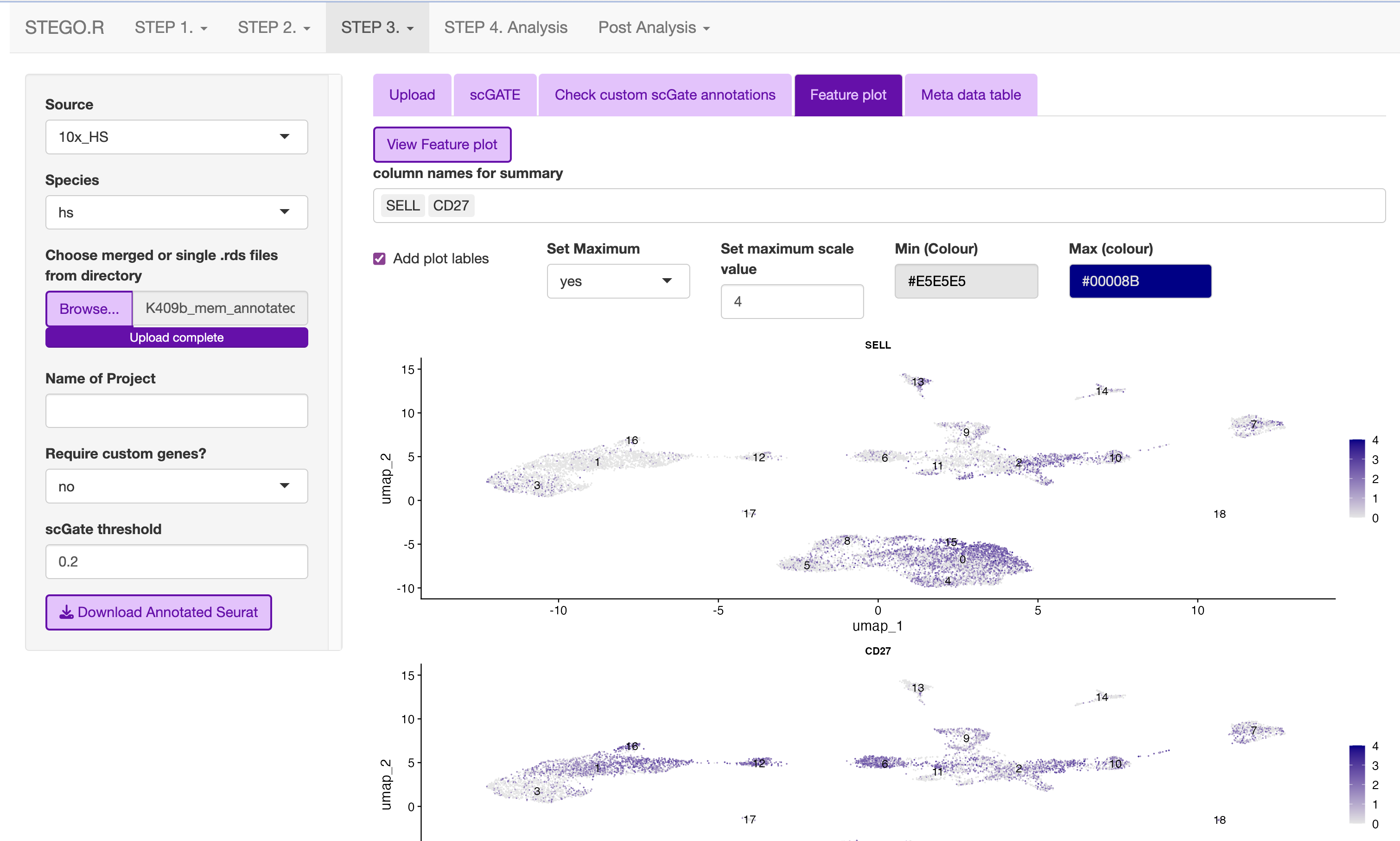
- Check that the cells express the markers under the “marker check” tab.
To run, click the ‘View Feature plot’
Design the panel to add into the nine custom databases in custom_db folder
Do not rename the master file. However, the file will need to be altered to set the markers. The user will need to define the name as well as the singature (gene list). If multiple genes are used, separate with ; as per the scGate documentation.
The user can alter the names in front of the _scGate_Model.tsv, while the latter is used to find each type of annotation.
To use scGate effectively, the genes within a set are read as OR (either of the marker need to be present), while the levels equate to AND i.e., All markers need to be present. These levels then need to be defined as positive or negative under the use_as column.
Use a fresh run of the app, so the new database is read into, otherwise it will be the default.
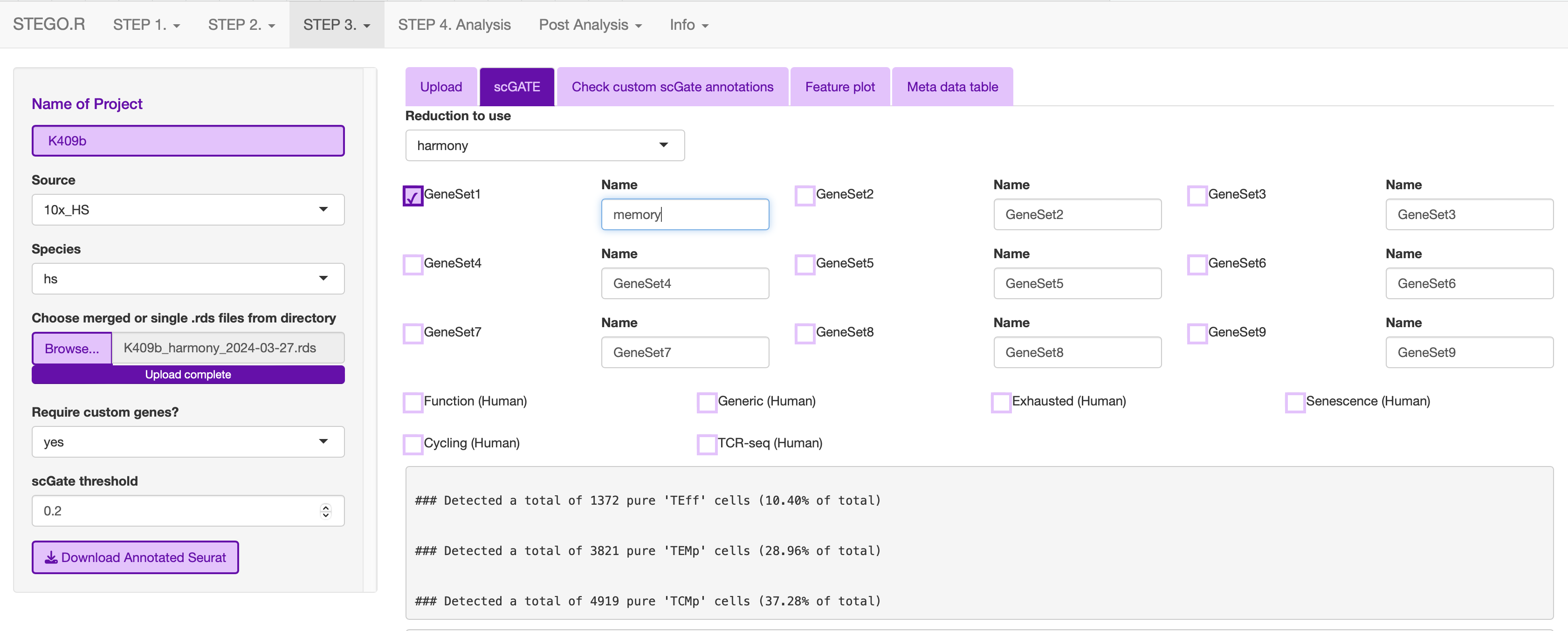
Run just the custom annotation needed.
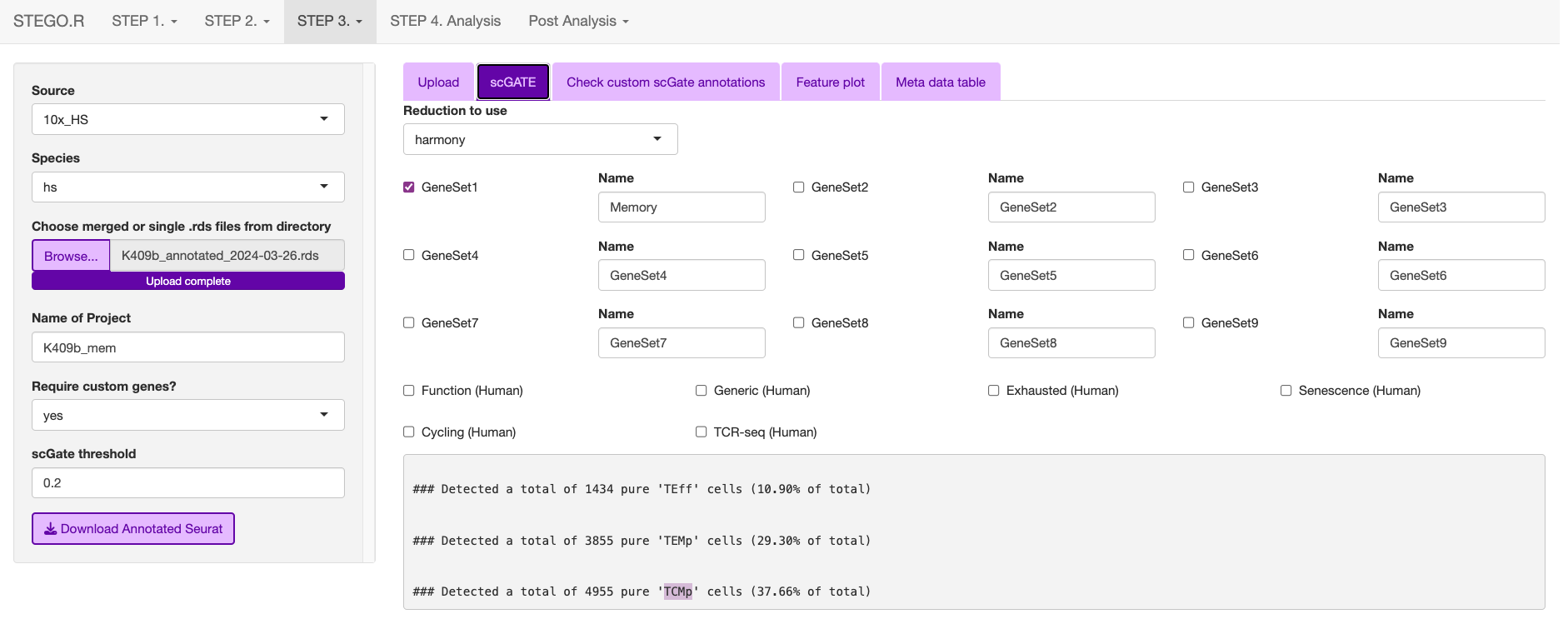
Check that there the signal overlaps with the gene expression, as per the feature plot. Once this is what you expect, download the object.

3d. Removing samples (optional)
This section allows the user to remove problematic cells based on any of the information in the meta data. This could be used to remove problematic samples post QC. Reasons for removal may be due to poor TCR-seq coverage. Also, you could limit the analysis to cells with both the GEx and TCR-seq present.
Additionally, this step can be used to extract certain samples. For instance, we extracted the
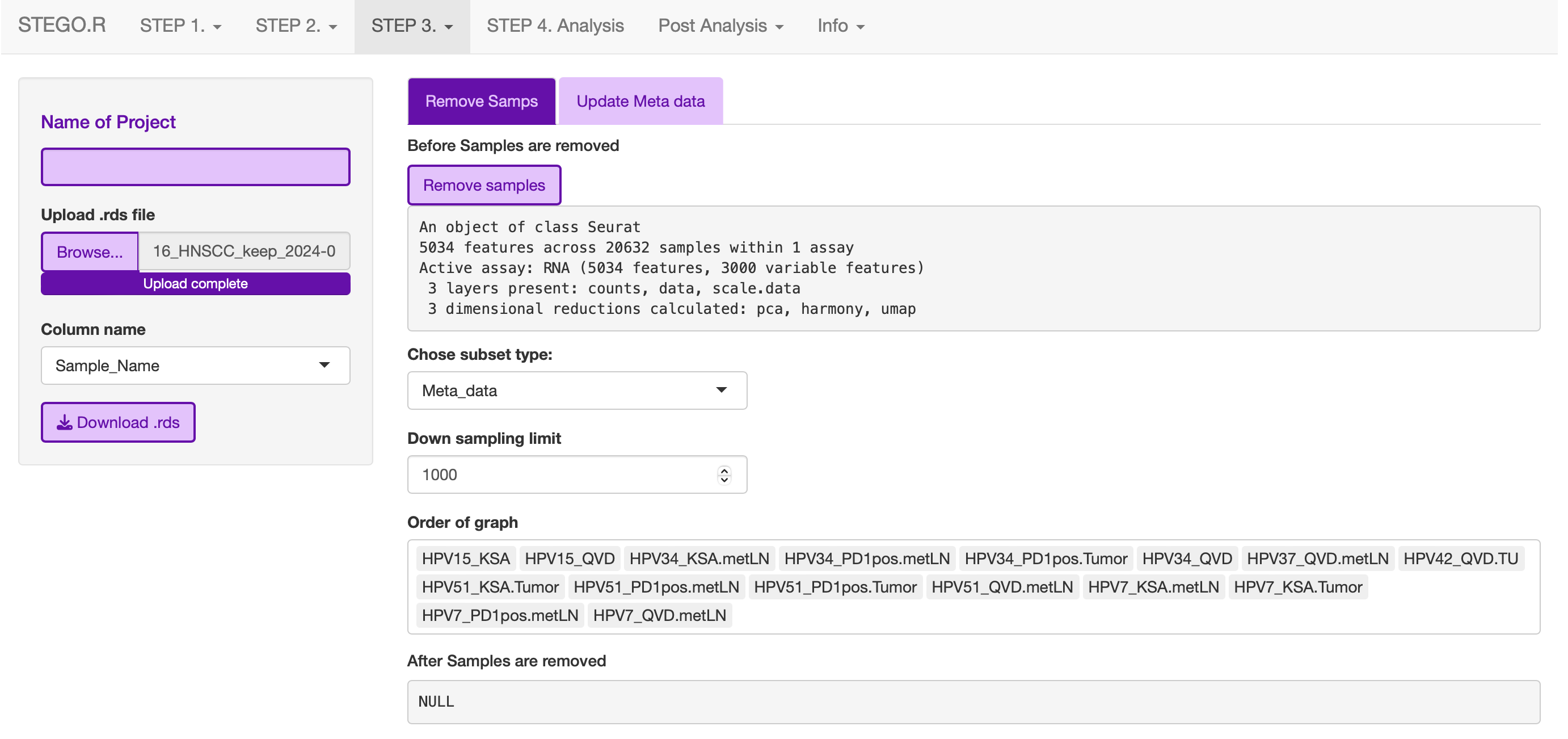
Under development: Downsampling. This section will be used for limiting to an even number of cell per annotation model and/or dataset origin to add a background data for smaller data to help with the FindMarker statistic.
3e. Re-formatting meta-data
In instances where the user has already done the QC, they will need to reformat their meta-data to make it compatible with STEGO.R formatting.
The currently available formatting is for scRepertoire that has:
TCR1 (Alpha v_gene j_gene) and TCR1_cdr3
TCR2 (BETA v_gene j_gene) and TCR2_cdr3